

Логично, что если сайта нет в поиске, то получение трафика из органической выдачи становится невозможным, а это потеря значительного сегмента аудитории для сайта. Если у вас подобная проблема, посмотрите перечень причин, по которым это могло произойти. SEO-специалисты агентства интернет-маркетинга «Директ Лайн» подготовили список самых распространенных проблем.
- Недавно созданная страница или сайт
- Запрет в robots.txt
- Запрет в метатеге robots
- Запрет в .htaccess
- Неуникальный контент
- Запрет на индексацию в CMS
- Дублированный контент внутри сайта
- Проблемы в структуре сайта
- Проблемы с ответом сервера
- Низкая скорость загрузки страниц
- На сайт наложены фильтры
- Проблемы с AJAX
- Сайт признан неглавным зеркалом
Недавно созданная страница или сайт
Чтобы новый сайт или страница попали в индекс поисковиков, потребуется определенное время. Если с ресурсом все в порядке, то новые документы должны появиться в поисковой выдаче Яндекса примерно в течение 1 месяца. Для Google этот срок может составлять от 1-14 дней.
Для ускорения попадания в выдачу рекомендуется:
- Добавить сайт в панели Вебмастера и Search Console.
- Уведомлять Яндекс о появлении новых страниц на сайте через специальную форму.
- Поделиться ссылкой нового документа в социальных сетях или на других сайтах, куда часто «заглядывают» краулеры поисковиков.
Запрет в robots.txt
Robots.txt – файл, находящийся в корне файловой системы сайта, содержащий директивы и инструкции для поисковых роботов. С помощью него можно разрешать или запрещать индексировать содержимое сайта: документы, папки.
Если у сайта есть проблемы с индексацией, следует проверить данный файл на отсутствие соответствующих запретов:
Весь сайт закрыт от индексации
User -agent: *
Disallow: /
Страница 1.html закрыта от индексации:
User-agent: *
Disallow: /1.html
Запрет в метатеге robots
Аналогичный принцип работы у метатега robots – в нем можно запрещать/разрешать индексацию конкретно взятой страницы. В любом случае, если есть проблемы с попаданием в индекс, его следует проверить:
Страница закрыта от индексации
<META name=”ROBOTS” CONTENT=”noindex, nofollow”/>
Запрет в .htaccess
Файл .htaccess также позволяет закрывать сайт от индексации, происходит это с помощью следующей директивы:
SetEnvIfNoCase User-Agent “^Yandex” search_bot
В данном примере индексация запрещается для краулеров Яндекса. Если требуется сделать это для других поисковиков, дублируем строчки и меняем название, например:
- Googlebot,
- Yahoo,
- Msnbot,
- Mail,
- Snapbot и т. д.
Неуникальный контент
Если на сайте публикуется неуникальный контент, то могут возникнуть проблемы с попаданием таких страниц в поисковую выдачу. Да, документ проиндексируется, но, вероятнее всего, будет признан неоригинальным, бесполезным и не покажется в органике.
В некоторых случаях, если сайт и домен имеют большой вес (речь о возрасте, посещаемости, ссылочном профиле и т.д.), то размещенный на его страницах неуникальный контент может быть выше в органической выдаче, чем оригинал-исходник. Но это исключительные случаи, поэтому рекомендуется проверять весь материал перед публикацией на уникальность. Сделать это можно в популярных сервисах:
- Text.ru,
- Etxt.ru,
- Content Watch и пр.
Запрет на индексацию в CMS
Практически любая из современных CMS позволяет закрывать сайт от поисковых краулеров. Например, в WordPress эта опция находится здесь: «Настройки – Чтение – Видимость для поисковых систем».
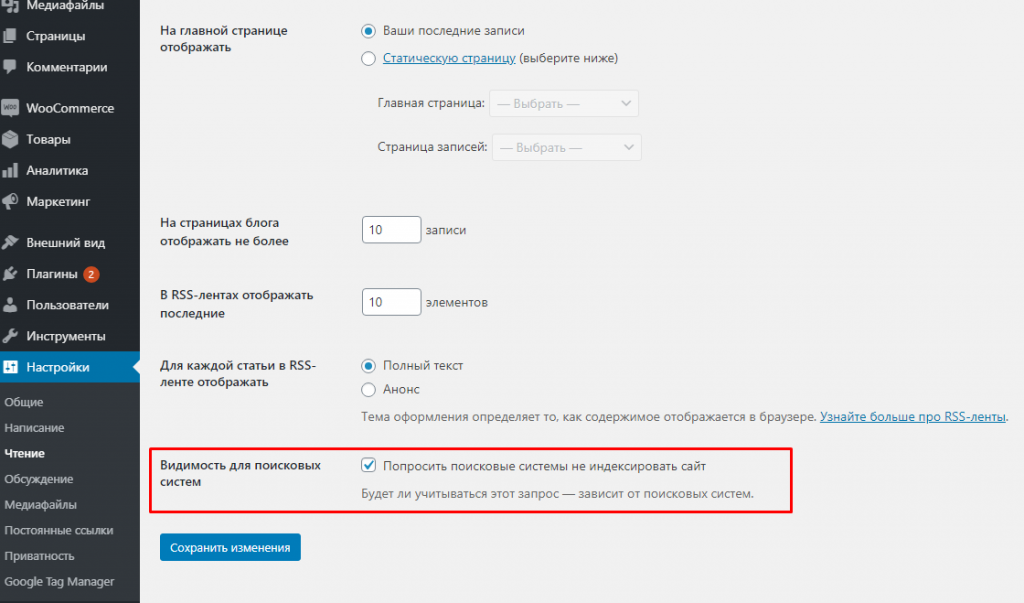
Если активировать эту настройку, то в HTML-коде сайта появляется метатег, указывающий поисковикам на запрет индексации ресурса.
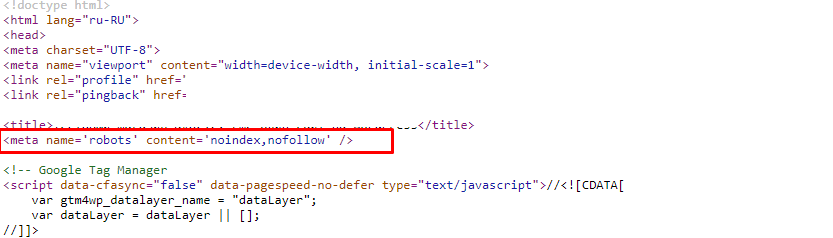
Это критически важная опция, но иногда активируется по ошибке вебмастера. Кроме нее, некоторые плагины, ориентированные на помощь в оптимизации ресурса, могут также запрещать поисковым роботам индексировать сайт целиком или его отдельно взятые разделы (страницы).
Дублированный контент внутри сайта
Дублирование контента может быть полным или частичным и возникает чаще всего из-за особенностей работы CMS. Это серьезная проблема, и критичность ее зависит от количества подобных страниц:
- При большом их количестве ухудшается индексация всего ресурса. Робот тратит краулинговый бюджет на нецелевые (в данном случае дубли) страницы, в итоге основные могут не попадать в поисковый индекс.
- Вероятность попадания под фильтры поисковиков.
- Иногда в выдаче появляется нецелевая страница.
Способы борьбы:
- Запретить индексацию дублей страниц вручную или с помощью плагинов.
- Использовать тег «rel canonical».
- Если контент навсегда «переезжает» на другую страницу, то используем 301 редирект.
Проблемы в структуре сайта
Грамотно спроектированная структура сайта помогает не только получить высокие позиции при ранжировании, но и оставляет у посетителей приятные впечатления, улучшая пользовательский опыт. Основные рекомендации по структуре сайта:
- Каждая страница должна относиться к своей категории (разделу). Помните, что роботу требуется определенное время на индексацию конкретно взятой страницы, и чем глубже она находится в структуре сайта, тем дольше этот процесс будет происходить.
- Отображайте структуру в файле Sitemap.xml.
- Закройте от индексации служебные разделы.
При проектировании сайта придерживайтесь следующей структуры: «Главная – Раздел (– Подраздел…) – Документ».

Проблемы с ответом сервера
При обращении к странице она должна отдавать 200 код ответа сервера. Код ответа – статус страницы:
- 200 – страница доступна для индексации (запрос успешно обработан).
- 301 – страница навсегда перемещена на другой URL-адрес. Запрета на индексацию нет.
- 4xx – страница не найдена, индексация невозможна.
- 5xx – страница временно недоступна, индексация также невозможна.
Выявить проблемные страницы можно с помощью специальных программ, например, Screaming Frog SEO Spider.
Низкая скорость загрузки страниц
Медленная загрузка страниц недопустима, особенно на мобильных устройствах. Рекомендуется придерживаться следующих показателей скорости загрузки: 2-4 сек. для мобильных устройств и 4 сек. для десктопов. Если скорость будет значительно ниже, то это станет знаком для поисковых систем о низком качестве ресурса. К тому же будут ухудшаться поведенческие факторы. В любом случае это приведет к негативным последствиям.
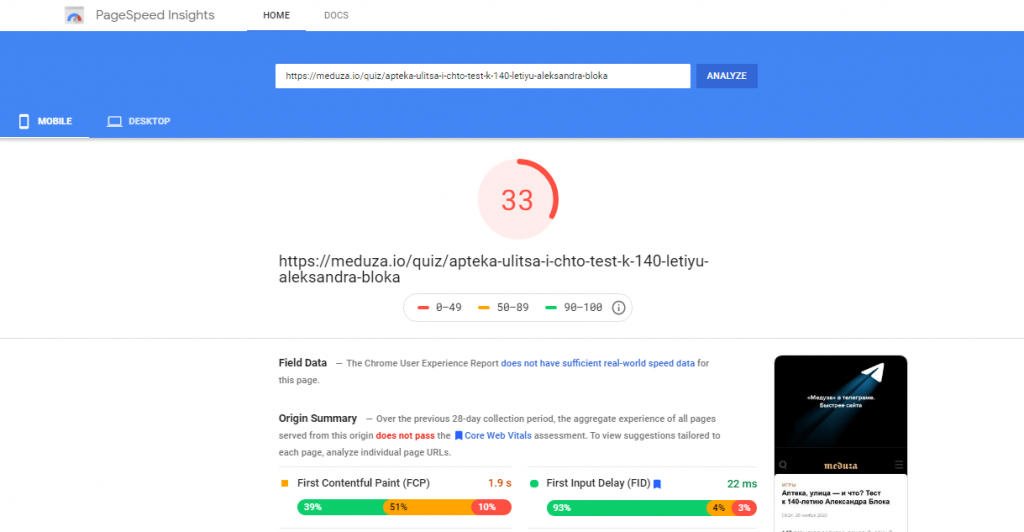
Способов ускорения несколько, основная их часть направлена на уменьшение веса документа. Проверить скорость загрузки можно с помощью инструмента Google PageSpeed Insights.
На сайт наложены фильтры
Под фильтры могут попасть не только сайты, использующие недобросовестные методы продвижения, но и вполне себе «белые», но имеющие некоторые проблемы. При попадании сайта под фильтр происходит значительное падение трафика или поисковых позиций. Как правило, изменения наступают резко, например, из органики выпало более 30-40% страниц.
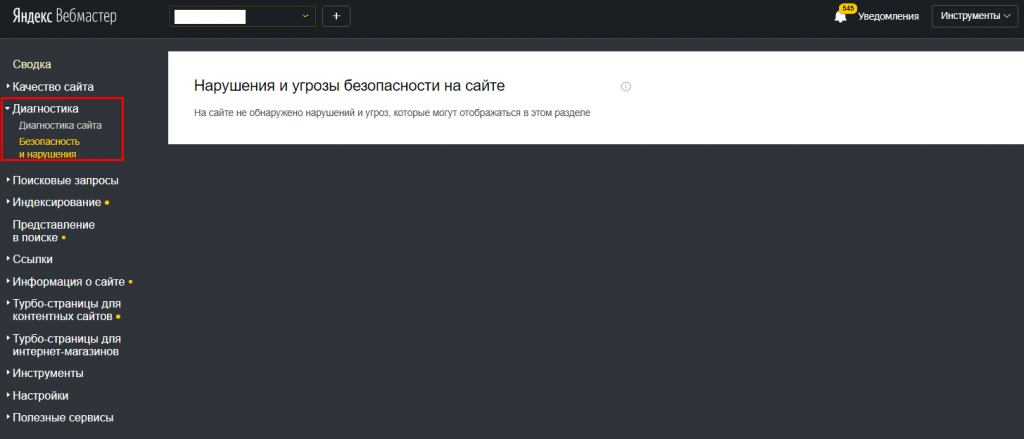
Говоря о Яндексе, уведомления о фильтрах могут находиться в панели Вебмастера: на общей странице или во вкладке «Диагностика» – зависит от того, были наложены ручные или автоматические санкции.
Гугл уведомляет только о ручных фильтрах, информацию можно найти в Search Console – «Проблемы безопасности и меры, принятые вручную»:
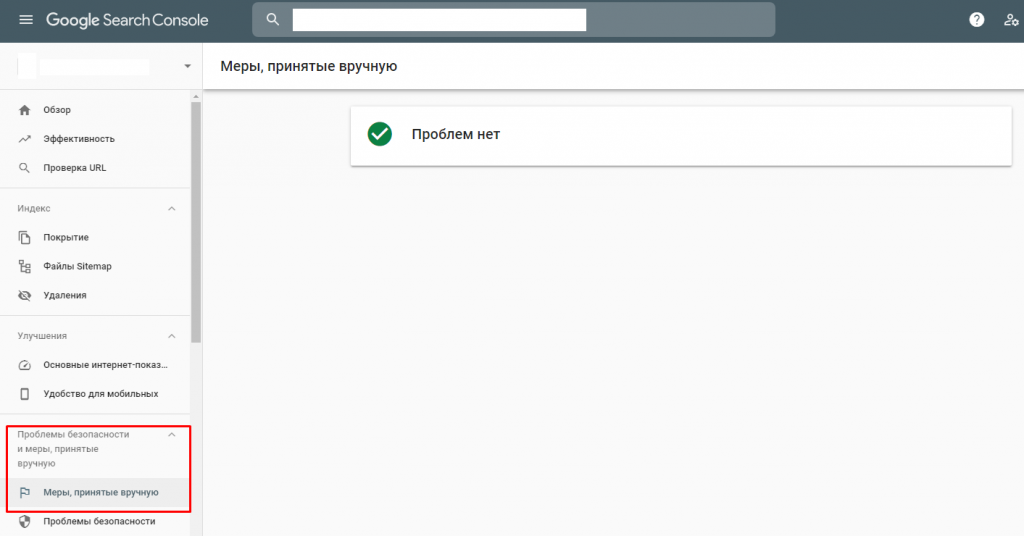
Кроме этого, существуют инструменты, которые способны определять фильтры:
- Xtool.ru – подходит для работы с санкциями Яндекса.
- Google Penalty Checker – для работы с Google.
Иногда вывести сайт из-под фильтра достаточно сложно (в отдельных случаях невозможно), но если такое случилось, то первое, на что должен быть направлен фокус действия, – устранение первопричины. Например, если на сайте преобладает дублированный контент, нужно удалить его или, что еще лучше, заменить на уникальный.
Проблемы с AJAX
Некоторые сайты работают с использованием технологии AJAX (асинхронный JavaScript), позволяющей обрабатывать запросы к серверу в фоновом режиме. С подобными страницами могут возникнуть проблемы при индексировании. Чтобы этого не произошло, обязательно создавайте каждому такому документу его HTML-версию и сообщайте об этом роботу с помощью следующего метатега:
meta name=”fragment” content=”!”
Как только робот встретит данный тег, он «поймет», что страница работает на AJAX, и переадресует все запросы по адресу:
example.com/?_escaped_fragment_=/category/page.html
вместо
example.com/ category/page.html
То есть HTML-версия этой страницы должна быть доступна по текущему адресу, но с добавлением параметра «?_escaped_fragment_=» (значение параметра пустое).
Если разместить метатег в HTML-версии страницы, то робот ее не проиндексирует.
Сайт признан неглавным зеркалом
Зеркалами признаются сайты, содержащие одинаковый контент, но доступные по разным адресам. В таком случае при ранжировании они объединяются в группу, а в выдаче участвует только один из них (главное зеркало).
Такая ситуация может произойти в следующих случаях:
- Некорректный «переезд» с HTTP версии сайта на HTTPS.
- Доступность сайта по адресам с WWW и без данного префикса.
- У сайта два доменных имени.
Чтобы проверить зеркала сайта, достаточно добавить его в Яндекс.Вебмастер и посмотреть домен в списке:
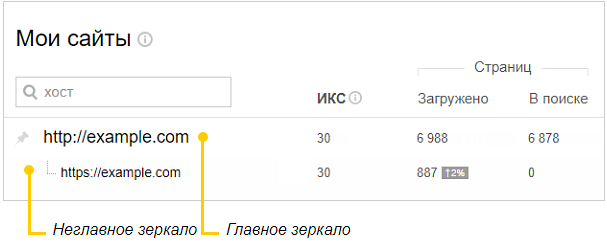
В этом примере у сайта два зеркала. Если бы они не являлись зеркалами, то отображались по отдельности в данном списке как два разных сайта.
Чтобы сменить главное зеркало, следует:
- Убедиться, что на двух зеркалах идентичный контент, а оба зеркала не ссылаются друг на друга.
- Далее оба зеркала следует добавить в панель Вебмастера.
- В файле robots.txt указать директиву «Host: домен_главного_зеркала.ru» в точном соответствии (например, с WWW или без).
- Далее ждем апдейта со стороны Яндекса, после которого в панели Вебмастера придет уведомление о смене главного зеркала.
- После рекомендуется дождаться момента, когда страницы основного (нового) зеркала начнут появляться в индексе. Потом настройте 301 редирект с неосновного зеркала.
Как правило, причиной отсутствия сайта или его отдельных страниц в индексе выступает одна из перечисленных выше, но, конечно, бывают и другие случаи, поэтому рекомендуем всегда анализировать ресурс комплексно.



