

Вот уже несколько лет LSI-копирайтинг (использование в SEO-текстах «слов, задающих тематику») остается крайне модной тенденцией. За это время здравая в основе идея успела обрасти мифами и чересчур смелыми трактовками.
- Выжимка: что оптимизаторы и копирайтеры думают о LSI
- Что такое LSI на самом деле?
- Недостатки LSI как метода оценки смысла текста
- Что нужно понимать, приступая к LSI-копирайтингу
- Как правильно готовить LSI-тексты?
- Мой вариант использования LSI
- Завершающий этап: усиливаем текст новыми расширениями
- Короткие выводы для тех, кто пролистал, не читая
- Мнение Александра Павлуцкого
Выжимка: что оптимизаторы и копирайтеры думают о LSI
Если читать подряд все, что написано по теме, то вырисовываются следующие тезисы.
- Аббревиатура расшифровывается как latent semantic indexing — скрытое семантическое индексирование.
- Текст для продвижения должен включать тематичные слова, а не только ключевые.
- К LSI-словам относятся а) синонимы основного ключевика б) слова, которые характеризуют и дополняют основной ключевик в) другие слова, имеющие отношение к теме статьи.
- LSI — это специальный новый алгоритм поисковиков против плохих SEO-текстов, «новая эра в копирайтинге».
- Также алгоритм нужен чтобы отличать тексты по смыслу. Например, чтобы разделить описание фильма «Тачки» от характеристик садового инвентаря.
- А еще LSI-текст должен иметь структуру, быть написанным простым языком, иметь приятный ритм, правильно распределять ключевые слова и тематичные расширения. Информация должна быть подана на уровне эксперта без грамматических и орфографических ошибок.
- Чтобы найти LSI, можно использовать подсказки поисковой системы, подсветки на выдаче, анализ текстов конкурентов (и сервисы, которые все это автоматизируют).
- Кое-где даже проскакивают заголовки «LSI убило SEO!» (ссылка, которую я автоматически вставляю после очередных похорон моей профессии).
Я только что сэкономил вам несколько часов на перелопачивание десятков статей по теме. Теперь попробуем разобраться, что тут правда, а что миф. А главное — как можно использовать это знание на практике.
Что такое LSI на самом деле?
Вот краткий и академически точный ответ:
LSI — сингулярное разложение терм-документной матрицы.
Это видео стало сеошным мемом — нагромождение терминологии вызывает смех. На мой взгляд, довольно странно бояться незнакомых терминов, если под рукой есть Google. Чтобы разобраться в матчасти на бытовом уровне, не надо быть профессором.
Например, можете почитать статью «Тематическое моделирование текстов на естественном языке» (авторы Антон Коршунов, Андрей Гомзин), она раскрывает эту и несколько смежных тем на весьма доступном уровне. Приведу несколько ключевых цитат.
Сначала о важности метода:
Зачастую документы, релевантные запросу с точки зрения пользователя, не содержали терминов из запроса и поэтому не отображались в результатах поиска (проблема синонимии). С другой стороны, большое количество документов, слабо или вовсе не соответствующих запросу, показывались пользователю только потому, что содержали термины из запроса (проблема полисемии).
В 1988 г. Dumais et al предложили метод латентно-семантического индексирования (latent semantic indexing, LSI), призванный повысить эффективность работы информационно-поисковых систем путём проецирования документов и терминов в пространство более низкой размерности, которое содержит семантические концепции исходного набора документов.
А теперь о том, как он реализуется.
Исходная точка — это терм-документная матрица:
Элементы этой матрицы содержат веса терминов в документах, назначенные с помощью выбранной весовой функции. В качестве примера можно рассмотреть самый простой вариант такой матрицы, в которой вес термина равен 1, если он встретился в документе (независимо от количества появлений),и 0 если не встретился.
 d1-d6 — документы, в первом столбце — термины
d1-d6 — документы, в первом столбце — термины
Легко видеть, что некоторые термины встречаются вместе в одном документе а другие — нет. Поисковые системы обладают базой текстов, которая в полной мере отражает особенности естественного языка. Это позволяет создавать огромные терм-документные матрицы и на их основе делать достоверные выводы о взаимосвязях между словами и принадлежности текстов к той или иной тематике.
Однако огромный размер хорош только в плане статистической достоверности. Напрямую работать с матрицей, которая получена из миллиардов текстов, невозможно, так как требует слишком больших машинных ресурсов. Вот тут и нужно сингулярное разложение — математическая операция, которая позволяет упростить терм-документную матрицу, выделив из нее только самые значимые тенденции. Это и есть «проекция в пространство более низкой размерности, которое содержит семантические концепции исходного набора документов».
(С матчастью практически закончили, дальше пойдет ближе к практике. Если интересуют детали — обратитесь к статье на habrahabr, где разобран простой рабочий пример и показаны этапы разложения).
Для нас больше всего важна последняя цитата, которая поясняет конечную цель всех этих процедур с точки зрения поисковой системы:
Для задач информационного поиска запрос пользователя рассматривается как набор терминов, который проецируется в семантическое пространство, после чего полученное представление сравнивается с представлениями документов в коллекции.
Именно так и можно найти документ, который релевантен по смыслу, хотя и не содержит ключевых слов запроса, то есть не обладает текстовой релевантностью в классическом понимании.
А еще поисковик может сравнить представление текста конкретной страницы с эталонными документами конкретной тематики. Если они будут сильно различаться — это серьезный сигнал о том, что с текстом что-то не так.
Например, типичный SEO-текст образца 2008 года состоит из «воды» и специально вставленных ключевых слов. «Вода» в нашем семантическом пространстве будет толкать текст к документам общей тематики, а ключевые слова — наоборот к конкретной теме. Это несоответствие не так сложно выявить.
Недостатки LSI как метода оценки смысла текста
Даже после поверхностного знакомства с методом, вы обязательно заметите, что LSI — это не магия, а всего лишь методика анализа текстов. Более того, она имеет ряд недостатков и упрощений:
- Текст в этом методе рассматривается просто как «мешок слов». Игнорируется их порядок и взаимосвязи в предложении.
- Считается, что слово имеет единственное значение.
- Смысл естественного текста не обязательно совпадает со значением набора слов. Иносказание, ирония, подтекст таким образом не распознаются.
- Сингулярное разложение позволяет работать только с самыми значимыми составляющими исходной матрицы. Часть данных при этом все равно теряется.
Почему я заостряю на этом внимание? Потому что теперь мы видим полную картину и наконец можем сделать несколько важных промежуточных выводов. Вернемся к началу статьи и трезво посмотрим на распространенные убеждения. Итак.
Что нужно понимать, приступая к LSI-копирайтингу
Во-первых, не стоит думать, что LSI — это волшебная таблетка.
Совершенно очевидно, что поисковые системы используют множество методик для определения «спамности» или «полезности» текста. Скрытое семантическое индексирование не универсально, у него есть недостатки. Поисковики безусловно знают о них и применяют LSI в комплексе с другими факторами. Например, огромное количество данных о качестве текста дают поведенческие метрики.
Так что просто натыкать в водянистый текст тематичных слов — не лучшая стратегия в долгосрочной перспективе.
Во-вторых, нет смысла приравнивать написание хороших текстов к LSI-копирайтингу.
А именно это и происходит. Вот скриншот из Википедии о LSI-копирайтинге:

Зачем присобачивать принципы, известные со времен этак Гомера, к одной узкой методике?
В-третьих, LSI в чистом виде — история в первую очередь про «угадывание» смысла запроса, классификацию документов по темам и фильтрацию спама, и только во вторую — про ранжирование.
Недавно делал конспект докладов об устройстве Яндекса. Там есть очень показательный момент. Александр Сафронов рассказывает о направлениях по лингвистике для улучшения качества поиска. В том числе о синонимах и о связанных расширениях, уточнениях, похожих запросах. То и другое принято объединять под ярлыком «LSI». Но!
Распознавание синонимов — это в большей степени «боль» самой поисковой системы. Там понимают, что текст может быть качественным и релевантным, даже не включая все варианты. Например страница с вхождением «купить» может прилично ранжироваться по ключам «покупка», «приобрести» и так далее.
А вот про расширения запроса Александр Сафронов четко говорит:
Скорее всего, релевантный документ, помимо слов запроса, будет содержать эти дополнительные слова (если он действительно хорошо отвечает на запрос пользователя).
Пример дополнительных слов:
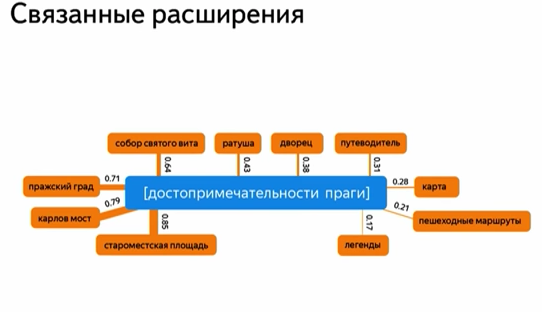
Заметьте, кстати, что здесь мы видим связи не только между отдельными словами. Поэтому очевидно, что для выделения расширений используется другая методика, а не LSI.

Второй нюанс в том, что базой для их получения является не только коллекция текстов, но и поисковые запросы. Их использование — это возможность для поисковика искать связи не по формальным критериям (встречаются ли в одном тексте или нет). Вариант: анализ связей между группой запросов, которую задал один пользователь в короткий промежуток времени (разумеется, с объединением данных по миллионам пользователей).
В-четвертых, для нахождения LSI требуются алгоритмы, работающие с довольно большим объемом текста.
Самый простой и часто предлагаемый путь — парсить подсветки Яндекса — и всегда работал не очень хорошо, давая очень скудный спектр слов, сейчас вообще малоактуален.
В-пятых, слова, которые предлагают сервисы, не являются результатом «настоящего» LSI, с которым работают поисковые системы (дальше эта оговорка упускается для краткости и как дань сложившимся понятиям).
Пункт прямо следует из предыдущего. Очевидно, что сервисы не имеют всех возможностей поисковика. Или, по крайней мере, не знают, на какой коллекции документов он определяет закономерности для себя. Тем не менее, связанную лексику сервисы могут генерировать неплохо. Для получения адекватного списка нужно как минимум работать с текстами из ТОПа по запросу (и лучше ТОП-50, а не ТОП-10). При этом, разумеется, тексты в ТОПе должны быть достаточно высокого качества. По низкочастотным запросам не всегда удается набрать достаточную базу.
Как правильно готовить LSI-тексты?
Ну вот мы и добрались до главного.
Если вы внимательно читали предыдущую часть, то могли задаться вопросом — а надо ли вообще этим заморачиваться? Ведь:
- Метод не идеален, имеет множество ограничений.
- Поисковики явно используют куда более сложные алгоритмы.
- Для получения адекватного списка нужна хорошая выборка данных, которую не всегда просто получить.
- Сами слова, задающие тематику, важны в первую очередь для защиты от фильтров. Конкретно в ранжировании помогают скорее не классические LSI-слова, а расширения из поисковых запросов.
- Писать тексты с LSI — значит дополнительно напрягать копирайтера. Иначе говоря — отвлекать его внимание от других важных элементов текста и оплачивать труд по более дорогой ставке. А еще — подсказывать путь, как можно написать статью внешне качественно.
- При этом все равно есть риск получить водянистый текст с кое-как вставленными терминами.
Я считаю, что мода на LSI (как и в случае большинства трендов) в значительной мере подогрета искусственно. Это в первую очередь способ позиционировать свои услуги по написанию текстов как более качественные либо продвинуть сервис по поиску тематичных слов. По крайней мере, у меня сложилось именно такое впечатление после чтения англоязычных материалов.
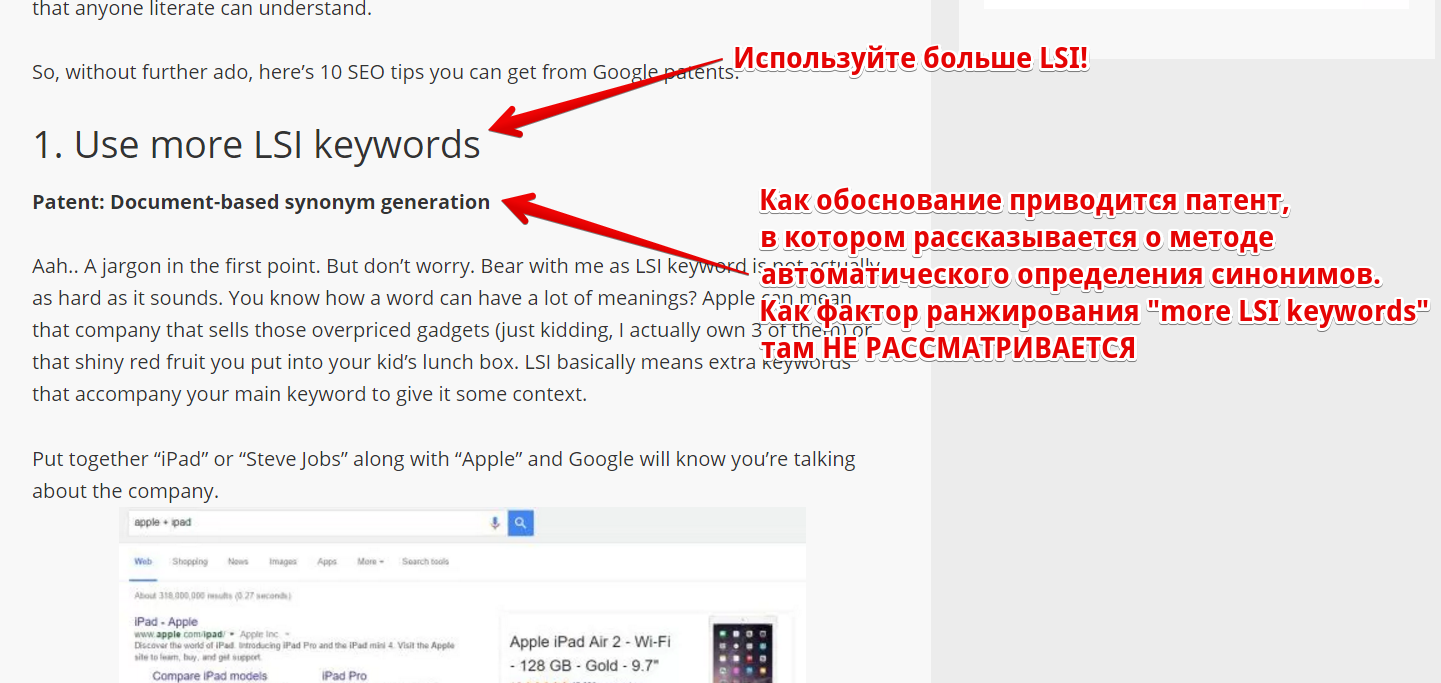
При этом зарубежные SEO-шники не особо утруждают себя поиском доказательств. Скриншот типичной статьи с советами по SEO:
(Привет всем, кто любит повторять мантру, что, дескать, интернет-маркетинг в России отстает на 3 года. В русскоязычных материалах я в целом видел более критичное отношение к теме, а сервисы в Рунете позиционируют свои услуги куда более аккуратно, не выдавая за волшебную кнопку. Впрочем, это субъективное наблюдение, чисто личные впечатления. Возможно, мне попались не те статьи. На Западе их очень много.)
Однако! Несмотря на все минусы, использовать LSI можно и нужно. Требуется только делать это эффективно и учитывать приведенный выше перечень проблем.
Мой вариант использования LSI
Схема очень простая.
1. Получаем список тематичных слов для каждой темы, которую планируем отдать копирайтеру. Сохраняем их леммы. Можно использовать бесплатный сервис Александра Арсёнкина: https://arsenkin.ru/tools/sp/ или платные текстовые анализаторы (убедитесь только, что они не ограничиваются парсингом подстветок)
2. Однако в ТЗ копирайтеру слова НЕ указываем. Главная задача — получить от него адекватный, решающий задачи пользователя текст. Именно на это и должен быть акцент.
3. Полученные на проверку тексты прогоняем через лемматизатор (тоже есть у Арсёнкина: https://arsenkin.ru/tools/lemma/) и сравниваем со списком LSI-лемм из первого этапа. Для быстрого сравнения списков можно использовать, например: https://bez-bubna.com/free/compare.php
4. Если значительной части LSI-лемм в тексте нет — смотрим его внимательнее. Возможно, с качеством текста что-то не в порядке. Если все хорошо и статья дает нормальный ответ на запрос — вставляем слова и публикуем. Если же есть проблемы — отправляем на доработку. Снова требуем сделать хорошо, а не просто добавить терминов.
В чем соль?
Во-первых, мы не смущаем копирайтера лишними требованиями.
Во-вторых, получаем полу-автоматический критерий для отбраковки плохих статей. Нормальный, человеческий текст будет содержать много LSI без всяких напоминаний. Если, конечно, тематичные слова были собраны корректно.
В-третьих, экономим собственное время на разбор LSI. Просто так выгрузить из сервиса слова и отдать на внедрение не получится. В них все равно будет попадать термины из смежных тематик (и не только: ошибок может быть много). Если давать LSI в ТЗ — придется чистить все результаты. Если использовать по моей схеме — только некоторые.
Завершающий этап: усиливаем текст новыми расширениями
После публикации текста нужно подождать пару месяцев, пока накопится статистика по переходам на него, а затем переработать контент, учитывая реальные запросы пользователей.
Выше я цитировал доклад сотрудника Яндекса, из которого следует, что наиболее эффективный путь получения дополнительных тематичных слов — работа с поисковыми запросами. Именно на основе этой идеи реализован инструмент по дополнительной оптимизации страниц в моем сервисе https://bez-bubna.com/ (точнее, его часть).
Общий принцип очень прост: смотрим состав поисковых запросов, сравниваем с текстом на странице и находим леммы, которые отсутствуют в тексте, но часто встречаются в запросах. Почему это работает?
Забудем о докладе Яндекса. Допустим даже влияния на продвижение основного ключа (главная функция LSI) слова из запросов не имеют. Тогда они способствуют продвижению по множеству низкочастотных запросов, которые немыслимо предусмотреть на этапе написания. Особая прелесть здесь в том, что можно исправить недостаточно эффективное семантическое ядро, быстро расширить семантику страницы.
Кроме того, поисковый спрос нестабилен. Появляются новые запросы, под которые еще очень мало контента в Интернете. Используя сервис, вы имеете шанс поймать эти перспективные ключи с малой конкуренцией и сделать контент более актуальным.
Вот пример — скриншот анализа моего поста об охвате записи ВК:

Метод эффективен даже в самом топорном исполнении — см. эксперимент по автоматической вставке ключей. На практике же требуется не просто впихивать новые расширения, но и добавлять контент (или по-новому расставлять акценты), чтобы страница давала адекватный ответ на эти новые запросы.
То есть: проработка страницы с помощью инструмента выходит за рамки простой текстовой оптимизации. Это работа сразу по нескольким фронтам, настоящее повышение качества контента. Это окупается (см. кейс с расчетом рентабельности: в нем не только вырос трафик, но и снизился процент отказов).
Короткие выводы для тех, кто пролистал, не читая
- LSI — один из современных подходов к анализу текстов. Имеет ряд ограничений и недостатков, это не единственный метод, который используют поисковые системы.
- Анализ связанной лексики наиболее эффективен в определении малоценных «водянистых» текстов и нахождении документов, которые могут соответствовать потребностям пользователя, хотя и не содержат ключевых слов, которые он ввел. Важность LSI как такового для ранжирования страниц с ненулевой текстовой релевантностью сомнительна.
- Использовать списки LSI-слов, которые генерируют разные сервисы, лучше всего на этапе приема работ для быстрой оценки и дополнительной оптимизации. В ТЗ же стоить включать более близкие к реальности критерии качества текста.
- Завершающий этап работы со страницей — усиление контента с помощью расширения семантики и проработки в плане интересов пользователя, которые не были приняты в расчет в начале (исходная точка — реальная статистика по запросам, которые давали трафик на страницу). На данный момент единственный публичный инструмент для автоматизации этого этапа есть в сервисе https://bez-bubna.com/.
Мнение Александра Павлуцкого
Мы уже давно ежемесячно даем от 1000 ТЗ по статьям. И с тех пор, как внедрили более активную работу по проработке подзаголовков + LSI, изменились две вещи:
1. С появлением списка LSI из 20-60 тематических слов — копирайтера можно дополнительно заряжать на более качественный материал.
Копирайтеру сложнее написать бред, если надо обязательно упомянуть слова, повышающие ценность и информативность статьи.
(Однажды клиент пришел с текстом по теме «насморк», в котором не было слова «сопли» — копирайтеру все показалось нормальным, а клиент не был спецом по ТЗ).
Часто копирайтеры слепо пишут в рамках ключей, которые им дают. LSI частично решает эту проблему.
2. Более детальная проработка ТЗ в итоге дала качественные результаты: средние позиции по статьям, средний показатель привлечения дополнительного трафа по микроНЧ, средняя посещаемость — все выросло.
В итоге — даже если отдельный параметр LSI имеет небольшую абсолютную величину, то как доп.фактор, который конкуренты не используют — он может быть существенным и давать хороший результат.
Тем более, времени занимает немного.
Не вижу причин не юзать.



Хорошая статья и дельный совет: “Мой вариант использования LSI”.
Хорошая статья. Хотя в интернете до сих пор спорят и говорят, что LSI – это туфта. Очень сложно найти адекватный ответ и понять, как работают поисковые системы. Приходится только методом тыка и экспериментов.