


Из анонса нового алгоритма Яндекса известно только, что от него могут пострадать страницы с переоптимизированным контентом. В качестве примера приводится анекдотичный фрагмент, где на все лады склоняется ключевик «SEO-текст». Рабочих способов различить «плохие» и «хорошие» тексты не приводится.
Работать наобум — не наш метод, так что попробуем выделить критерии самостоятельно.
- Объект и методика
- Баден-Баден — запросный или документный?
- Чем вообще отличаются документный и запросный фактор/фильтр?
- Проверка гипотезы о запросозависимости
- Сравнительный анализ пострадавших и не пострадавших страниц
- Простая аналогия для тех, кто хочет понять методику интуитивно
- Пример расчета
- Поведенческие факторы
- «Классическая» тошнота
- «Академическая» тошнота
- Показатель вариативности текста
- Показатель «водности» текста
- Объем текста в словах
- Частота встречаемости биграмм
- Частота встречаемости триграмм
- Обсуждение результатов
- Дополнительный показатель естественности
- Коротко о главном
Объект и методика
В первую очередь меня интересовало, при каких условиях санкции накладываются на более-менее приличные страницы, когда вполне можно читать, не морщась в каждом абзаце от корявой оптимизации. Анализ крайних случаев — с сотней вхождений, выделенных жирным — вряд ли принес бы ценные данные, тут и так все ясно.
Исследование опирается на простую идею — сравнить характеристики двух групп страниц одного и того же сайта:
- где наблюдается значительная просадка трафика в момент запуска Баден-Бадена.
- где посещаемость стабильна или выросла.
Благодаря анализу внутри одного хоста мы уравниваем множество факторов и можем быть более уверены в выводах.
Всего удалось собрать 68 сайтов, где трафик с Яндекса существенно просел после 22 марта 2017 (спасибо всем, кто прислал свои проекты на анализ!).
В SEO-исследованиях размер выборки — это своеобразный культ, однако я уверен, что куда важнее ее однородность. Поэтому беспощадно удалял из рассмотрения все, что могло исказить результат.
В частности, я отбраковал сайты:
- С малым количеством посещаемых url (если документ до фильтра приносил менее 100 посетителей в месяц с Яндекса, падение трафика статистически недостоверно).
- Где трафик с Google также имел выраженную тенденцию к снижению.
- С высоким разнообразием контента (тематически или структурно).
- С высокой зависимостью от сезона.
- Где также сработал хостовый фильтр.
- Оптимизированные совсем топорно/не несущие вообще никакой полезной информации (первый критерий был полностью формализован, второй — частично).
Также были вынесены из основного исследования интернет-магазины и сайты услуг (их было меньше в выборке; в отличие от статейных проектов, текст здесь зачастую не играет роли и само его наличие порой говорит о чрезмерной оптимизации).
В итоге остался 31 сайт и 4297 документов для анализа.
Прежде чем перейти к сравнению характеристик успешных и потерявших трафик страниц, необходимо было прояснить еще один важный вопрос.
Баден-Баден — запросный или документный?
Как я писал в недавнем обзоре публикаций по Баден-Бадену, из официальных заявлений следует, что санкции «первой волны» применяются к странице (анонс от 23 марта). Однако многие SEO-специалисты называют Баден-Баден запросозависимым, указывая на то, что позиции сильнее всего просели у ключевых фраз, под которые текст затачивался в первую очередь.
Это не простой спор о терминах, а ключевой момент. Давайте разберемся.
Чем вообще отличаются документный и запросный фактор/фильтр?
(Употреблять «фильтр» по отношению к Баден-Бадену не вполне точно, использую для краткости).
Различие — внутри алгоритмов поисковой системы.

Может ли изменение общего рейтинга повлиять на позиции только группы запросов? Сколько угодно! Чтобы было совсем наглядно — еще одна табличка. Допустим, есть три url — A, B, С c определенными значениями релевантности по 3 запросам:
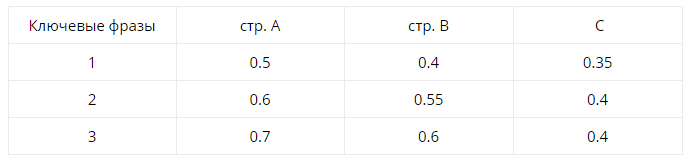
Допустим, страница B попала под санкции, ее общий рейтинг оштрафовали на 0.1. Смотрим на релевантность по запросам:
Что произойдет после применения штрафа?
- Первый запрос просядет.
- Второй останется где был.
- Третий останется где был.
А теперь представим, что санкции были наложены одновременно с апдейтом. Причем незадолго до него более успешный конкурент по третьему запросу (страница A) поменял что-то на странице и его релевантность упала до 0.45.
Тогда третий запрос вырастет (0.45 против 0.5).
Вывод? С позициями страницы, которая попала под документный фильтр, может твориться все что угодно (хотя общий тренд, разумеется, к понижению). А ведь это очень упрощенная модель. Не учтен многорукий бандит, возможные технические ошибки при сборе и так далее.
Говорить о том, что фильтр позапросный только на основании разной динамики позиций у ключевых слов страницы нельзя. Это лишь гипотеза.
Проверка гипотезы о запросозависимости
Рассказываю кратко, так как все это по-прежнему преамбула к основному исследованию. Для документов, где было выявлено существенное падение посещаемости вследствие Баден-Бадена:
- Была собрана статистика по ключевым фразам, которые давали трафик за 3 недели до фильтра.
- Фразы были разбиты на 2 группы: а) не содержащие лемм, отсутствующих в тексте б) содержащие леммы, которых нет в тексте.
- Подсчитан трафик для каждой из групп, определена доля в общем трафике.
- Аналогичные подсчеты для трех недель после фильтра.
Как должна измениться доля трафика по ключам из второй группы? Это фразы, прицельная оптимизация под которые не проводилась (иначе был бы задействован самый банальный фактор текстовой релевантности — вхождение всех слов запроса), по которым трафик поступал «естественным образом».
Если фильтр запросозависимый, то доля трафика по таким ключам должна вырасти: ведь Баден-Бадену их карать не за что.
Что видим в итоге? Картина прямо противоположная:
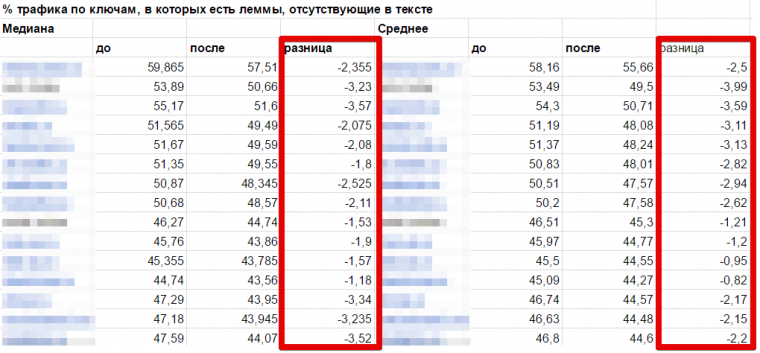
Для всех сайтов выборки (!) и медианное и среднее значение доли трафика по таким ключевым словам снизилось. В среднем на 2,6% — немного, но этого достаточно, чтобы с абсолютной уверенностью заявить, что уж прироста точно нет.
Трафик в данном случае максимально надежный критерий, так как в нем аккумулируется и отражается информация обо всех позициях по всем запросам. А не о паре-тройке десятков, специально отобранных оптимизатором.
Вывод: Баден-Баден проявляет себя как документный фильтр, гипотеза о запросозависимости не подтвердилась.
Не хочу занимать место в статье объяснением, почему уменьшение доли трафика по запросам с отсутствующими леммами — дополнительный аргумент в пользу вывода. Поэтому мини-конкурс: кто лучше всех раскроет этот момент в комментариях — получит 5 проверок на баланс в SEO-прорыве (а еще славу и уважуху). Дерзайте!
Кстати. Раз алгоритм карает страницы, то делаются совершенно бессмысленными часто встречающиеся заявления вроде «при Баден-Бадене, наложенном на документ, происходит просадка на N позиций». Мне попадались варианты «7-30», «20-30», «10-40».
Вот результаты понижения на 3 (ну, максимум на 5 — смотря что считать исходной датой) позиций:
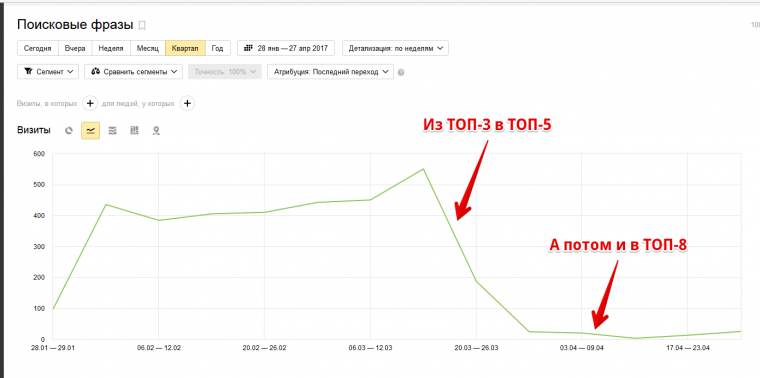
Падение существенно, наличие санкций несомненно. Так что никакой конкретной (или даже приблизительной) цифры назвать нельзя. Изменение позиций ведь зависит не только от размера штрафа но и от «силы» конкурентов.
Сравнительный анализ пострадавших и не пострадавших страниц
Наконец добрались до главного. Так как характер санкций — документный, то анализ сильно упрощается. Нет необходимости рассматривать все нюансы ранжирования по парам запрос-документ. Можно работать с самой страницей, ее наполнением.
Для каждой из 4297 страниц выборки рассчитывался ряд показателей. Затем они усреднялись сначала для конкретного сайта, а затем оценивались для выборки в целом.
Для каждого сайта и фактора применялась формула:
D = (B — N)/N*100%
где
- D — разница между значением показателя на «хороших» и «плохих» страницах, выраженная в процентах;
- B — средний показатель страниц сайта под Баден-Баденом;
- N — средний показатель нормальных страниц (где трафик стабилен или вырос).
Делить на N необходимо чтобы определить разницу в %, отследить, насколько сильно отличаются данные для разных факторов и сравнить их относительную значимость. Просто так сравнивать разницу между «нормой» и «плохими» страницами нельзя — ведь разные факторы измеряются в разных величинах.

Простая аналогия для тех, кто хочет понять методику интуитивно
Допустим, появилась новая болезнь и ученые ищут как с ней бороться. Одни люди поправляются за 1 день, другие — за месяц. Люди из этих двух групп очень разные — они отличаются ростом (метры!), весом (килограммы!), количеством гемоглобина в крови (хмм, не помню). Как можно понять, какое свойство организма дает защиту или наоборот приводит к тяжелой болезни?
Во-первых, надо изучить группы «здоровяков» и болевших долго, которые как можно больше схожи. Во-вторых, найти, какие характеристики организма у них разнятся сильнее всего. Отличие, конечно же, нужно считать не в метрах и килограммах, а переводить в проценты. Тогда можно сравнить любые показатели. Вот и вся суть формулы.
Возвращаемся к SEO.
Часть оценивавшихся факторов оперирует понятием «стоп-слов». Для повышения достоверности они рассчитывались дважды — с коротким и расширенным списком. Значимых различий для этих вариантов выявлено не было. Результаты ниже приведены по измерениям с расширенным.
Пример расчета
Давайте разберем на простом примере. Допустим на сайте есть 6 статей. Мы хотим понять, отличаются ли «хорошие» от «плохих» по объему текста.
Собираем вот такую статистику:
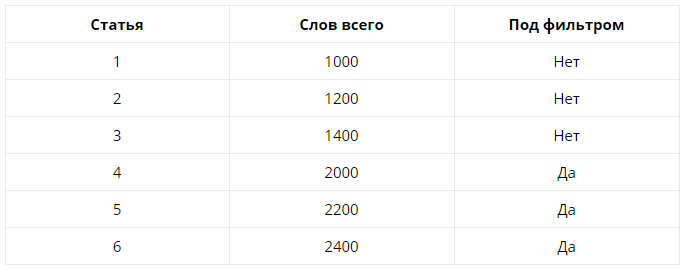
Теперь считаем среднее значение для страниц 1, 2, 3 (без фильтра) и для 4, 5, 6 (под фильтром). В первом случае это (1000 + 1200 + 1400)/3 = 1200. Во втором — (2000 + 2200 + 2400)/3 = 2200. Теперь, имея на руках средние значения, мы можем определить среднюю же разницу между теми, кто попал под фильтр и теми кто устоял.
Считаем:
2200 — 1200 = 1000.
Напоминаю, что мы считаем объем текста в словах. Но в дальнейшем нам нужно будет сравнить между собой самые разные показатели, которые измеряются в других единицах. Только так мы поймем, какие из них важны, а какие нет.
Поэтому теперь рассчитаем не просто разницу, а относительную разницу, т.е. переведем в проценты от нормы: 1000/1200*100% = 83%.
Теперь берем каждый сайт выборки и проделываем то же самое. Считаем среднее значение — вуаля, видим, насколько в целом по выборке «хорошие» страницы отличаются от «плохих» по объему текста. И так для каждого показателя.
Конечно, пример чисто для наглядности. На 6 объектах делать наблюдения нельзя, в реальности маленькие сайты я не рассматривал. Ну и как вы можете увидеть ниже, различия по объему текста совсем не в районе 80%.
Поведенческие факторы
Согласно заявлениям представителей Яндекса, в работе Баден-Бадена учитывается поведение пользователей. Поэтому в первую очередь я проверил базовые показатели активности посетителей на странице.
Результаты сравнения по формуле:
- процент отказов: —0,9%;
- средняя длительность посещения: 0,6%;
- глубина просмотра: 1,3%;
«Классическая» тошнота
Это всего лишь квадратный корень из количества вхождений самого частого слова. Результат несколько неожиданный: —2,7% (знак минус!). То есть тошнота на «нормальных» выше, чем на попавших под Баден-Баден. Мы вернемся к этому позже.
«Академическая» тошнота
Более сложный показатель, так как учитывает вхождения разных слов по отношению к объему текста. D = —3%. Точно так же — на «нормальных» текстах она оказалась выше.
Показатель вариативности текста
Рассчитывается как разница между единицей и отношением «уникальные леммы/уникальные словоформы». D = —1,8%. Чуть больше на нормальных.
Показатель «водности» текста
Разница между единицей и отношением «количество слов после очистки стоп-слов/количество слов в исходном тексте». Страница, вообще не содержащая стоп-слов будет иметь водность 0, содержащая только стоп-слова — 1.
D = 8,7%. Так-так! Водность на страницах, попавших под Баден-Баден, значительно выше.
Наличие «воды» в тексте оценивается многими метриками и это всегда негативный сигнал. Например, может страдать рейтинг по фактору Yandex Minimal Window.
Объем текста в словах
D = —1,8%. На нормальных чуть больше. Статистическая достоверность под сомнением, скорее нужно говорить об отсутствии разницы. Во всяком случае, дело не в размере как таковом (к комментариям под анонсом в блоге Яндекса были мнения, что фильтр накладывается на «портянки»).
Частота встречаемости биграмм
Для вычисления берется сумма числа вхождений трех самых частых биграмм — то есть сочетаний двух слов (например, типичный оборот в SEO-тексте «купить окна» сводится к биграмме «купить окно»). Сумма делится на количество слов в тексте, чтобы оценить относительную частоту.
D = 5,9%. Видим существенно больший показатель у «плохих» страниц.
Частота встречаемости триграмм
Расчет аналогичен, только берутся триграммы («Купить пластиковые окна» => «купить пластиковый окно»).
D = 7,8%. Ого! Триграммами-то тексты под Баден-Баденом спамят еще сильнее!
Обсуждение результатов
Значение D по модулю (просто чтобы сравнить, как сильно отличаются разные показатели, независимо от того, больше или меньше они на страницах, где орудовал Баден-Баден):
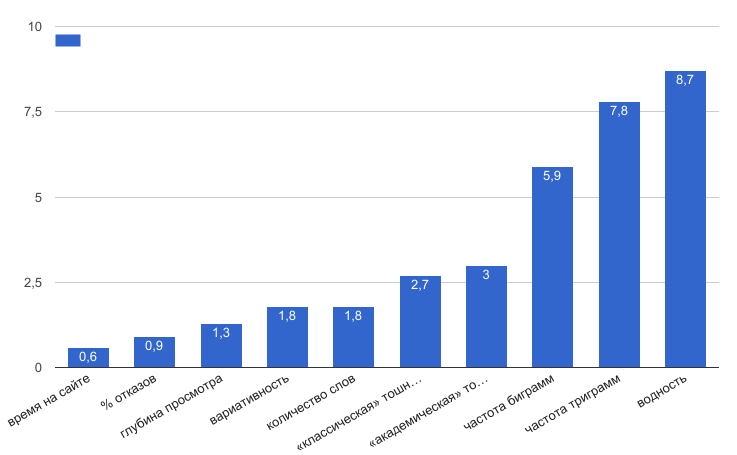
Поведенческие факторы предсказуемо оказались в самом хвосте списка. Очевидно, паттерны поведения на разных страницах весьма сходны. Поэтому утверждение о том, что Баден-Баден учитывает поведение пользователей я рассматриваю в том смысле, что поведение учитывалось во время обучения алгоритма на выборках переоптимизированных и естественных текстов.
Максимально значимые отличия демонстрируют водность, частота триграмм и биграмм.
Любопытно, что «тошнота» текста на страницах, попавших под Баден-Баден, даже ниже чем на нормальных. Это наблюдение не нужно рассматривать как общее правило. Вспомните, что для анализа были отобраны только сайты с более-менее приличными текстами. Наверняка среди других проектов полно документов с обрушившимся трафиком и огромной тошнотой. Обилие вхождений Яндекс не приветствует уже давно (см. эксперимент).
Однако очевидно, что высокий показатель встречаемости слова — далеко не самый важный и универсальный признак спамного текста.
Вдумаемся в тот факт, что пострадавшие страницы одновременно имеют более низкую тошноту и более высокий рейтинг биграмм/триграмм. То и другое вычисляется по сходному принципу: встречаемость слова/количество слов и встречаемость биграммы/количество слов. Очевидно, что в нормальных текстах частота слова и частота биграммы, в которую оно входит, будет коррелировать. В спамных же этот порядок нарушен: частота отдельных слов оказывается не такой уж большой, зато они постоянно сбиваются в n-граммы.
Если совсем просто. Допустим, у нас есть хороший экспертный текст про пластиковые окна. Очень маловероятно, что в нем все слова из набора «пластиковый», «окно», «купить» будут постоянно встречаться вместе (попробуйте напрячь воображение). А вот если у копирайтера есть задача втиснуть десяток ключей в водянистый текст, при этом оставаясь в заданных рамках по «тошноте» — то иначе и получиться не может. Автор не сможет использовать слова из запроса где-то еще, кроме специально вставленных поисковых фраз.
Дополнительный показатель естественности
Чтобы проверить и заодно описать это наблюдение более строго, я рассчитал дополнительный показатель. Количество вхождений топовых триграмм в текст поделил на сумму вхождений слов из их состава. Получилась простая характеристика, описывающая, насколько часто популярные слова в тексте объединяются в триграммы.
Разница между страницами под Баден-Баденом и «нормальными» составила 9,4% (!). Это очень много (больше, чем любая другая метрика в этой статье).
Не тешу себя надеждой, что выделил именно те факторы, с помощью которых Яндекс выбирает, какие страницы считать переоптимизированными, а какие — нет. Наверняка алгоритм использует множество других метрик, куда более сложных. Однако более чем вероятно, что они тем или иным образом связаны с «водностью» и n-граммами. Различия слишком существенны, чтобы их игнорировать.
Важнейший результат — в том, что разница между очень похожими внешне «хорошими» и «плохими» текстами отлично улавливается сравнительно простыми показателями. Их вполне можно использовать для определения страниц, которые требуют особого внимания и первоочередных доработок на них.
В конце концов, наша задача проще, чем у Яндекса. Ему нужно было покарать спамные документы, задев как можно меньше добропорядочных. Нам же требуется просто расставить приоритеты; понять, на чем в первую очередь ловятся «плохие» страницы и исправить это. Особенно актуальна подобная проверка для сайтов, попавших под хостовый фильтр а также молодых проектов, где невозможно выделить проблемные страницы путем анализа трафика или позиций.
Коротко о главном
- Баден-Баден проявляет себя как фильтр, наложенный на документ (или хост), без привязки к конкретным запросам.
- Постраничный характер санкций позволяет провести сравнительный анализ документов с разной динамикой трафика после 22 марта и использовать результаты на практике.
- В ходе исследования не было выявлено прямое влияние поведенческих факторов. Различия относятся в первую очередь к текстовым метрикам.
- Для статейных сайтов относительно высокого качества выявлены следующие характеристики попавших под санкции страниц: высокая водность, высокая частота биграмм и триграмм, плохо коррелирующая с частотой входящих в них слов. Проще говоря, спамные тексты по мнению Яндекса содержат много стоп-слов, а также избыток устойчивых сочетаний из нескольких слов. При этом сама по себе частота устойчивых сочетаний может быть не слишком большой.
- Для интернет-магазинов и корпоративных сайтов наблюдаются схожие тенденции, однако в этом случае размер выборки не позволяет делать выводы с высокой степенью уверенности.
- «Тошнота», как академическая, так и классическая, не является самостоятельным полезным сигналом.
- Для возврата трафика требуется повышение естественности текста. По всей видимости, Яндекс оценивает ее комплексно. Любые показатели следует воспринимать только как ориентиры, демонстрирующие лишь часть общей картины.
p.s. Не забываем о конкурсе! Кто объяснит, почему при наложении санкций снижается не только общий трафик, но и доля визитов по запросам, содержащим отсутствующие в тексте леммы?
p.p.s. Скоро напишу о том, как на практике применять полученные данные для работы с попавшими под раздачу сайтами. А также что делать тем, кто предусмотрительно хочет защитить свои проекты (напоминаю, что алгоритм, по словам Яндекса, еще не разгулялся в полную силу).
p.p.p.s. Лайки и репосты мотивируют делать новые исследования и делиться результатами 
Многих заинтересовало, чем проверять указанные в статье показатели. Выложил первую версию сервиса для этого (см. анонс).



